关于安尔法
- 惊爆,传感器直降!
- 实施预测性维护时的分析注意事项
- AI引领矿业新纪元,勘探开发迎来智慧革命
- 完美交付 | 蒙古国可汗矿业200万吨炼焦煤重介质选煤厂调试完毕!
- 【连载3】人工智能解惑进阶|伯克利AI课程
- 俄罗斯采矿业的全球影响力与未来展望
- 共创全球矿业新篇章:安尔法加入中国选冶出海联盟!
- 【连载2】人工智能解惑进阶|伯克利AI课程
- [连载1]人工智能解惑进阶|伯克利AI课程
- 携手千年波斯 | 中国煤机制造挺进中亚!
- 倒计时4天!|2024俄罗斯新库兹涅茨克国际矿业展览会即将开幕!
- 展会预告|ALPHA与您相约2024俄罗斯新库兹涅茨克国际矿业展览会!
- 百团大战 | XRT预抛废(干选)的竞争现状
- 冠军球队的秘密
- 它来了它来了!安尔法重磅推出锂电池系列传感器,为新能源汽车发展赋能!
- 安尔法助力井工煤矿提升设备智能运维和生产安全!
- 3分钱!F35战斗机同水平预测性维护和设备智能运维云服务!
- 2022年度中国名校四川校友足球赛 | 安尔法携手千页科技、拜安科技赞助中国矿业大学校友队!
- 数字感知新未来 | 安尔法“算法定义硬件”产品线!
- 运维大数据的价值!安尔法智能托管运营做深矿山服务!
- 行业喜讯 | 安尔法设备预测性维护系统入编《选煤厂智能化技术与装备推荐目录》!
- 安尔法与首都国投的结晶|年产60万片工业物联网硬件工厂开始试生产!
- 2022开年大单 | 安尔法喜获蒙古国戈壁资源公司煤泥水系统智能运维及运营长期合同
- 分布式光纤测温系统在叙永选煤厂安装完毕,数据成功接入!
- 喜讯 | Alpha再次引领前沿技术,微震预警入选中国工程院发布的《全球工程前沿2021》!
- 砥砺前行迈进新征程 | 安尔法智控股改及北交所上市签约仪式圆满完成!
- Alpha提供矿山设备智能化硬件升级和免费数据处理平台
- 安尔法诚聘董事会秘书
- 智能化暴风眼丨持续性诊断需求
- 没有中枢神经的工业物联网就是“植物人”
- 量身定制!基于光纤分布式测温技术的皮带传动设备的PHM系统!
- 矿业实现智能化转型的4座大山
- Alpha(安尔法)获得成都市高新技术企业专项补贴!
- Alpha智能物联采选系统分析服务
- 安尔法携手中科芯未来落地海南琼海!
- 没有几十万行代码,你还敢做大数据?
- 双喜临门!基于物联网的传感器项目完成签约,落地山东济宁与海南琼海
- 求贤若渴!安尔法招聘:液压、电气及机械工程师
- 求贤若渴!安尔法招聘:液压、电气及机械工程师
- 今日头条|Alpha为拉法基旗下水泥厂提供预测性维护服务!
- 喜报!你要悄悄申请“发明专利”,然后惊艳所有人!
- 近乎白给的双11特惠!超低费为各大选煤厂已有传感数据接入分析诊断服务!
- 效果显著!PdM系统攀煤选煤厂稀介泵油箱预警
- 地下矿山实施防碰撞系统的三大挑战
- 无线遥控技术在铲运车上的应用
- 止损280万!PdM系统攀煤选煤厂又一次成功预警
- 芯片就绪-安尔法新一代智能传感器!
- 谁是2020年硬核创新之最?最有潜力的28家成长企业或将揭晓
- ALPHA为浩特定制矿山智能管理运维系统
- ALPHA招募经销商或代理商
- 疫情防控|安尔法热成像测温筑牢疫情防控第一道防线
- 抗击疫情,武汉加油!疫情下的安尔法预测性维护如何持续发挥奇效?
- 人才紧缺!招聘!安尔法!国际大公司!
- Alpha到访巴西淡水河谷 | 新一轮技术培训指导
- 安尔法选煤智能化技术在德里绽放 | 印度国际选煤展
- 最快能有多快?智能预测性维护系统成功监测到复选泵严重故障
- 准备好了吗?安尔法即将以智能化闪耀印度国际选煤大会(附智能化资料)
- 创举丨全球首个5G+智能化选煤厂示范项目揭幕
- Alpha阶段性工作汇报!(最近安尔法都在忙什么?)
- 重磅消息 | 信息系统集成及服务资质认定取消啦!
- 欢迎大家莅临2019北京煤炭展 | China Coal& Mining Expo
- 香港客户来访|遥控技术交流与深度传感器合作
- Alpha机器学习时间进入”亿小时”阶段 | 2年增长1040倍
- 巴西淡水河谷客户来访|实地考察与进一步合作
- 智能遥控案例|井下采矿设备的智能遥控等级
- ALPHA受邀《马钢矿业资源集团智能矿山规划设计方案》评审会!
- 淡水河谷!安尔法在南美巴西的20000+测点预测性维护部署
- [免费赠阅]最新缅甸矿业投资指南暨少数赞助商招募
- 矿业智能化的十个超级创新公司
- 进军东南亚-安尔法预测性维护在知名半导体行业公司厂区设备的应用
- 安尔法预测性维护成功进入南美咯!巴西
- “低成本”预测性维护让选厂智能化“触手可及”
- 安尔法预测性维护传感器获本安防爆认证
- 插播现场一条叙永选煤厂现场新闻,PdM预测到电机的一个小问题?儿童节开始的特惠预维套装了解一下?
- 菲律宾采矿业概况
- 智能迷你堆取料机-Alpha智能装备
- Alpha气动阀门在蒙古国UHG选煤厂成功应用并完美替代欧美产品
- 安尔法预测性维护全新月收费模式-开启行业最底价,还赠送3个试用名额,要试试吗?
- Alpha闪耀汉诺威工业展
- 人工智能项目的六投三不投(转)
- 预测性维护是最佳的维护方式-振动仪监测和在线传感监测的区别
- 预测性维护成效持续显现-石窑店选煤厂刮板机提前排障
- 西安煤博会-安尔法受邀宣讲选煤厂智能化预测性维护
- 亲测有效-安尔法成功预测到叙永选煤厂设备故障并提前排障!
- 工业物联网应用场景丰富,“设备运维”是的切入点
- 石窑店选煤厂预警系统由泰戈特监督验收
- 安尓法智控在山西焦煤的选煤厂智能化演讲交流
- 预测性维护在西南地区选煤厂第一个试点!
- 一文读懂工业物联网的矿业智能化应用
- 无线智能故障预警系统在石窑店选煤厂调试成功
- 风电领域设备预测性维护
- 预测性维护给矿山带来的变革
【连载3】人工智能解惑进阶|伯克利AI课程
原创 粟登洋 安尔法智控Alpha工业物联 2024-08-23
-
将SVD应用于特定数据集
-
在特定背景下分析PCA的结果
-
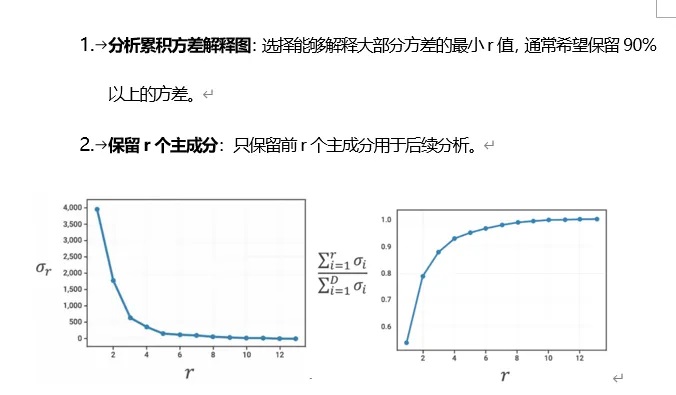
绘制并解释奇异值(碎石图)
-
选择r值以达到期望的方差捕获水平
-
在Python中实现K-Means算法
-
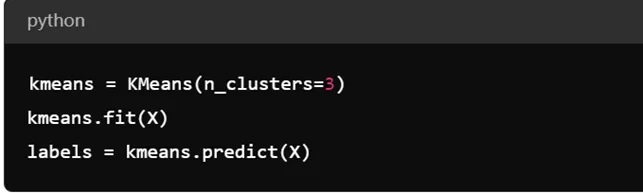
在Python中应用K-Means函数
-
在给定初始数据集的情况下解释K-Means和PCA的结果
-
使用scikit-learn进行K-Means聚类
-
比较两种不同的质心初始化方法(k-means++ vs. 随机初始化)
-
比较在给定数据集上的多种聚类技术的结果
-
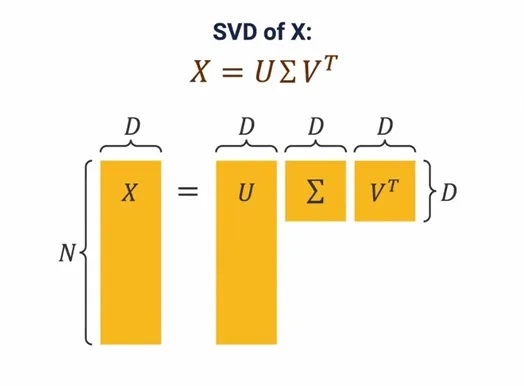
数据归一化:首先通过减去均值并除以标准差对数据进行归一化处理。
-
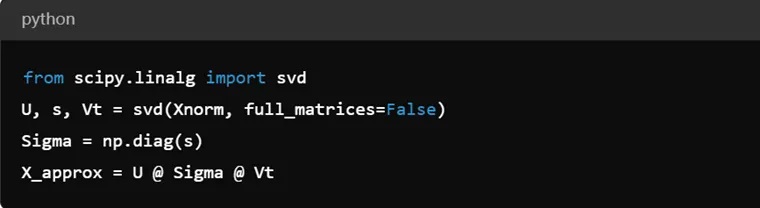
执行SVD:在归一化的数据上执行奇异值分解(SVD)。
验证分解:通过矩阵乘法重构原始数据,并检查结果是否与归一化数据一致
思路:












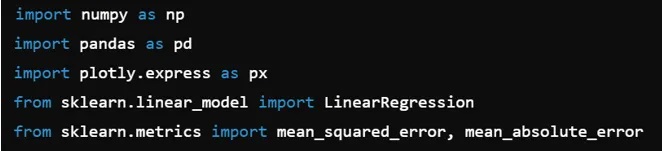
1.区分线性模型和非线性模型
2.使用Plotly拟合简单线性回归线
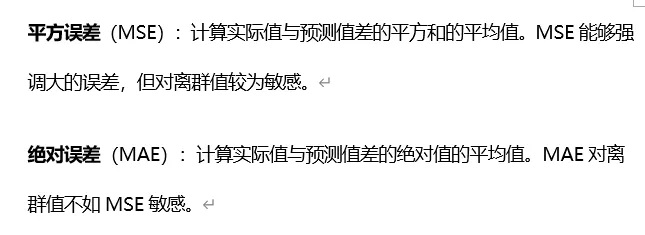
3.计算平方误差和绝对误差
4.识别损失函数对离群值的反应
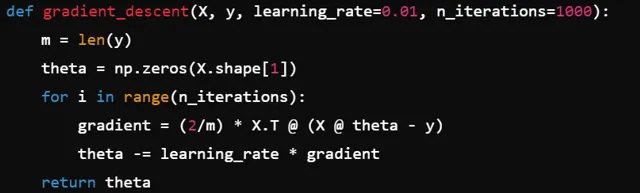
5.应用多种技术来最小化损失函数
6.使用多元线性回归模型预测结果
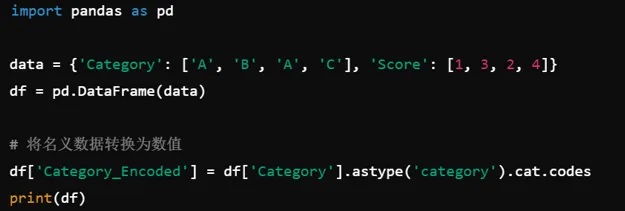
7.识别数据集中序数、名义和分类数据